UUID nedir? RFC 9562 ve modern benzersiz tanımlayıcılara tam rehber
Hızlı Özet
- Her modern veritabanı, dağıtık sistem ve API benzersiz tanımlayıcılar kullanır — ve 2026’da onları düzenleyen standart temelden değişti
- Her modern veritabanı, dağıtık sistem ve API benzersiz tanımlayıcılar kullanır — ve 2026’da onları düzenleyen standart temelden değişti.
- RFC 9562’yi anlamak: modern UUID standardı
Editoryal Süreç
SectoJoy tarafından incelenmiş ve 14 Haziran 2026 tarihinde yayınlanmıştır. Bu makale, ürün detayları, örnekler veya araç kılavuzları değiştiğinde güncellenir. Son güncelleme 14 Haziran 2026.
SectoJoy
Pratik SaaS ürünleri oluşturmaya odaklanan, iOS ve web uygulamaları geliştiren bağımsız bir geliştiriciyim. yapay zeka SEO konusunda uzmanım ve akıllı teknolojilerin sürdürülebilir büyüme ve verimlilik sağlama potansiyelini sürekli araştırıyorum.
Her modern veritabanı, dağıtık sistem ve API benzersiz tanımlayıcılar kullanır — ve 2026’da onları düzenleyen standart temelden değişti. UUID (Evrensel Benzersiz Tanımlayıcı, Universally Unique Identifier), herhangi bir merkezi koordinasyon olmadan bilgisayar sistemleri arasında bilgiyi tanımlayabilen 128-bitlik bir etikettir. Yeni RFC 9562 (Mayıs 2024’te RFC 4122’nin yerini aldı) kapsamında manzara değişti: UUID v4 rastgele ID’ler için hâlâ tercih edilen seçim, ancak UUID v7 artık veritabanı birincil anahtarları için önerilen standart çünkü zaman sıralı yapısı B-ağacı dizinlerinin parçalanmasını önler.
Bu rehber tüm resmi kapsar: UUID’ler nasıl çalışır, hangi sürüm ne zaman kullanılır ve nasıl doğru uygulanır.
RFC 9562’yi anlamak: modern UUID standardı
UUID, benzersizliği pratikte garanti edilen 128-bitlik bir sayıdır — hiçbir merkezi otorite gerekmez. Vikipedi‘ye göre iki UUID’nin çarpışma olasılığı sıfıra o kadar yakındır ki gerçek dünya uygulamaları için imkansız kabul edilir. Farklı ekipler verileri bağımsız olarak etiketleyebilir ve ID’lerinin çarpışmayacağından emin olabilir.
Mayıs 2024’te IETF, RFC 9562‘yi yayımlayarak eski RFC 4122’yi emekliye ayırdı. Güncelleme, hem benzersiz hem de zamana göre sıralanabilir ID’lere ihtiyaç duyan modern dağıtık sistemlerin taleplerine bir yanıttı. Üç yeni sürüm tanıtıldı: v6, v7 ve v8.
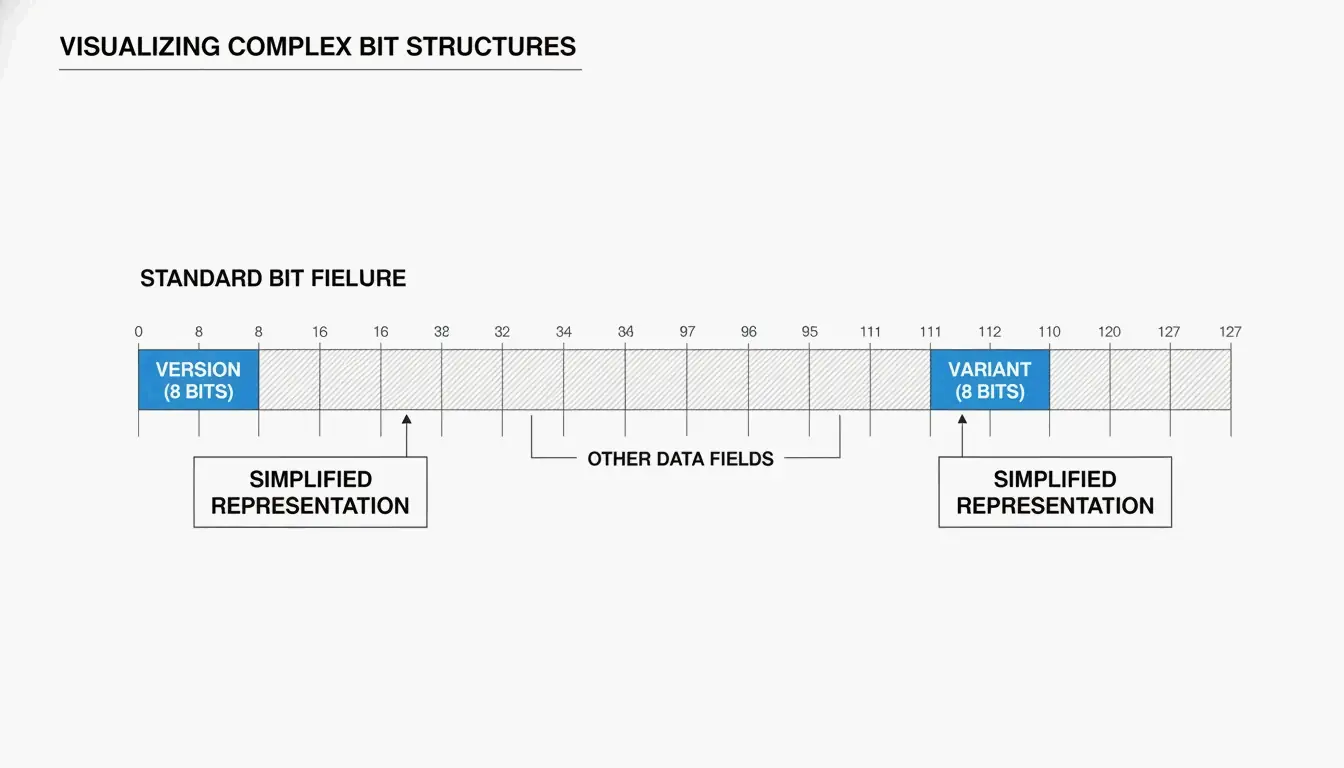
Bir UUID’nin anatomisi: sürümler ve varyantlar
Bir UUID’yi genellikle tirelerle beş gruba bölünmüş 32 onaltılık karakter olarak görürsünüz (8-4-4-4-12):
550e8400-e29b-41d4-a716-446655440000
^
version
İki temel alan size UUID’nin nasıl üretildiğini söyler:
| Alan | Konum | Size ne söyler |
|---|---|---|
| Sürüm bitleri | 7. baytın ilk 4 biti (3. grubun ilk karakteri) | Hangi algoritmanın kullanıldığı (ör. “4” = v4, “7” = v7) |
| Varyant bitleri | 9. bayt | UUID varyantı — RFC 9562 bir 10 bit deseni kullanır |
SnapUtils‘nın açıkladığı gibi, varyant bitleri modern RFC 9562 UUID’lerini eski Apollo veya Microsoft biçimlerinden ayırır.
UUID v7 neden veritabanları için yeni altın standart
UUID v4‘ün en büyük dezavantajı tamamen rastgele olmasıdır. Bir B-ağacı dizininde birincil anahtar olarak kullanıldığında, veritabanı yeni satırları öngörülemez konumlara eklemek zorundadır. CreateUUID‘ye göre bu, “sayfa bölmelerine” (page splits) neden olur — veritabanı yer açmak için verileri sürekli yeniden düzenlemek zorundadır ve bu da daha yavaş yazmalara ve israf edilen belleğe yol açar.
UUID v7, ID’nin başına bir 48-bit Unix Epoch zaman damgası (milisaniye hassasiyeti) yerleştirerek bunu çözer. Bu, ID’leri monoton artan hale getirir — yeniler her zaman eskilerden büyüktür. Veritabanı basitçe dizinin sonuna ekleyebilir ve size sıralı bir tamsayının performansını UUID’nin küresel benzersizliğiyle birlikte sunar.
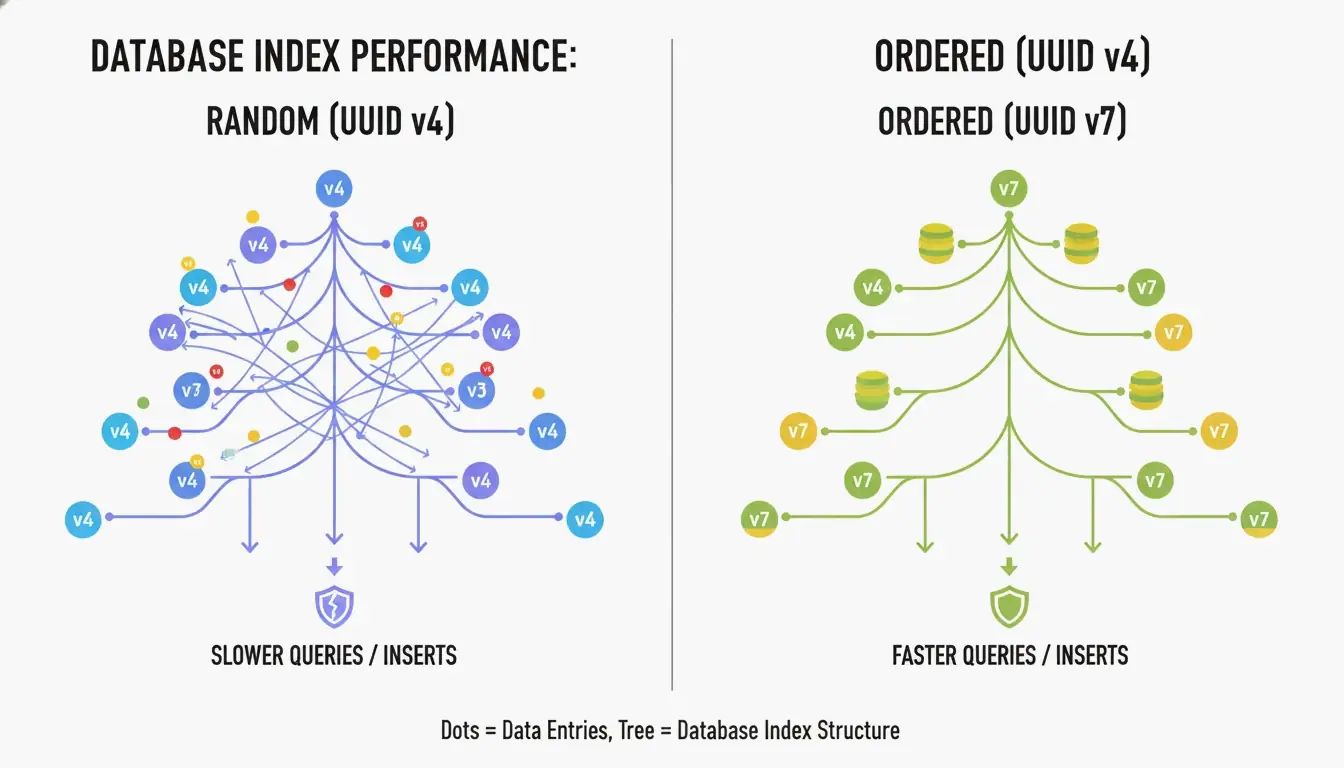
UUID v7 zaman ve entropiyi nasıl dengeler
UUID v7 kalan 74 biti bir CSPRNG (kriptografik olarak güvenli sözde rastgele sayı üreteci) ile doldurur. Vikipedi‘ye göre, %50 çarpışma olasılığına ulaşmak için saniyede yaklaşık 1 milyar UUID’yi 85 yıl boyunca üretmeniz gerekir. Herhangi bir gerçek uygulama için UUID v7 etkin bir şekilde çarpışmaya karşı bağışıktır.
Depolama en iyi uygulamaları: Binary(16) vs. String(36)
UUID’leri nasıl depoladığınız, hangi sürümü kullandığınız kadar önemlidir:
| Depolama biçimi | Alan | Dizin performansı | Öneri |
|---|---|---|---|
| Binary(16) | 16 bayt | Yüksek (kompakt) | En iyi uygulama |
| Doğal UUID türü | 16 bayt | Yüksek (optimize) | PostgreSQL için en iyisi |
| Dize (Char 36) | 36–72 bayt | Düşük (parçalanmış) | Kaçının |
SnapUtils dizeler yerine her zaman doğal türleri kullanmanızı önerir. PostgreSQL‘de doğal uuid türü, standart dize tabanlı sorguları desteklerken verileri kompakt bir 16-bayt ikili biçimde depolar.
UUID vs. GUID: Bir fark var mı?
GUID (Küresel Benzersiz Tanımlayıcı, Globally Unique Identifier), UUID standardının Microsoft uygulamasıdır. Tarihsel olarak bayt sıralamasında (endianness) bir fark vardı — erken Microsoft GUID’leri ilk üç alan için little-endian kullanıyordu, standart UUID’ler ise big-endian (ağ bayt sıralaması) kullanıyordu (SnapUtils).
2026’ya gelindiğinde bu çoğunlukla bir adlandırma kuralıdır. RFC 9562 kapsamında özdeş çalışırlar. .NET’teki Guid.NewGuid(), Python’daki uuid.uuid4() ile tamamen uyumludur. Windows/Azure çevrelerinde “GUID”, Linux ve açık kaynak topluluklarında “UUID” duyarsınız.
Modern UUID’leri uygulamak: dil dil
| Dil | UUID v4 | UUID v7 |
|---|---|---|
| Python | Yerleşik uuid modülü |
uuid6 veya uuid7 paketi |
| JavaScript | crypto.randomUUID() |
uuid npm paketi (v10+) |
| PostgreSQL | gen_random_uuid() (PG 13+) |
Doğal uuidv7() (PG 17+) veya uzantılar |
| .NET | Guid.NewGuid() |
Topluluk paketleri |
| Rust | uuid crate (v1.7+) |
v7 özelliğiyle uuid crate |
Belirleyici ID’ler: UUID v5
Belirli bir girdi (ör. URL veya kullanıcı adı) için her seferinde aynı ID’ye ihtiyaç duyarsanız UUID v5 kullanın. Bir ad alanı UUID’sini ve bir ad dizesini SHA-1 ile özetler — merkezi bir veritabanını sorgulayamadığınızda tekilleştirme için mükemmeldir.
UUID v1’in gizlilik dersi
UUID v1 bir zaman damgası ve bilgisayarın MAC adresini kullanır. Donanım bilgilerini sızdırdığı için büyük ölçüde terk edildi. Ünlü bir örnek: Melissa virüsü‘nün yaratıcısı, enfekte Word belgelerindeki UUID’ler onun belirli MAC adresini içerdiğinden yakalandı.
Gelişmiş RFC 9562: v6, v8 ve özel UUID’ler
RFC 9562, dağıtık sistemlerin niş ihtiyaçları için özel sürümler ekledi:
| Sürüm | Amaç | Ne zaman kullanılır |
|---|---|---|
| v6 | Yeniden sıralanmış v1 zaman damgası — v1’in hassasiyetini koruyarak sıralanabilir | Eski v1 sistemlerinin taşınması |
| v8 | Özel — geliştirici tanımlı veriler için 122 bit | Deneysel veya satıcıya özel şemalar |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
Null yer tutucu |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
Aralık uç noktası işaretçisi |
Sonuç
RFC 9562, benzersiz tanımlayıcıları modern bulut çağı için güncelledi. Pratik kılavuz:
- Veritabanı birincil anahtarları → Zaman sıralı, parçalanmasız eklemeler için UUID v7 kullanın
- Genel rastgelelik → UUID v4 hâlâ tamamen uygun
- Tekilleştirme → UUID v5 size belirleyici ID’ler verir
- Depolama → Her zaman Binary(16) veya doğal UUID türleri kullanın, asla dizeler
Eylem maddesi: Veritabanı şemalarınızı kontrol edin. Milyonlarca satırı olan tablolarda birincil anahtar olarak UUID v4 kullanıyorsanız, UUID v7’ye geçiş, dizin parçalanmasını önemli ölçüde azaltabilecek ve sorguları hızlandırabilecek basit bir değişikliktir.
Sıkça Sorulan Sorular
Bir UUID, bir GUID ile aynı mıdır?
İşlevsel olarak, evet. GUID, UUID standardının Microsoft uygulamasıdır. RFC 9562 kapsamında davranışları özdeştir — bunları .NET, Java ve Python uygulamaları arasında birbirinin yerine kullanabilirsiniz.
Gerçek bir senaryoda iki UUID hiç çarpışabilir mi?
Matematiksel olarak mümkün, pratikte imkansız. UUID v4 için, %50 çarpışma olasılığına ulaşmak üzere yaklaşık 2.71 kentilyon ID üretmeniz gerekir. Generate-Random.org‘ya göre, saniyede 1 milyar UUID’yi 85 yıl boyunca üretmek size yalnızca tek bir çarpışma için %50 şans verir.
UUID’leri veritabanımda dizeler olarak mı yoksa ikili olarak mı depolamalıyım?
Her zaman Binary(16) veya doğal UUID türünü (PostgreSQL’de kullanılabilir) tercih edin. 36 karakterlik bir dize, iki katından fazla alan tüketir ve dizin aramalarını ve birleştirmeleri önemli ölçüde yavaşlatır.SnapUtils, RFC 9562’nin performans avantajlarının depolama kompakt kaldığında en üst düzeye ulaştığını belirtir.
UUID v4 yerine UUID v5’i ne zaman kullanmalıyım?
Belirleyici ID’lere ihtiyaç duyduğunuzda, yani aynı girdinin her zaman aynı UUID’yi ürettiği ve bir veritabanını sorgulamadığı durumda v5 kullanın. Tam rastgeleliğe ihtiyaç duyduğunuzda ve tanımlayıcının kaynağına tersine mühendislik uygulanamayacağından emin olmak istediğinizde v4 kullanın.
Sıkça Sorulan Sorular
UUID vs. GUID: Bir fark var mı?
GUID (Küresel Benzersiz Tanımlayıcı, Globally Unique Identifier), UUID standardının Microsoft uygulamasıdır. Tarihsel olarak bayt sıralamasında (endianness) bir fark vardı — erken Microsoft GUID’leri ilk üç alan için little-endian kullanıyordu, standart UUID’ler ise big-endian (ağ bayt sıralaması) kullanıyordu (SnapUtils). 2026’ya gelindiğinde bu çoğunlukla bir adlandırma kuralıdır. RFC 9562 kapsamında özdeş çalışırlar. .NET’teki Guid.NewGuid(), Python’daki uuid.uuid4() ile tamamen uyumludur. Windows/Azure çevrelerinde “GUID”, Linux ve açık kaynak topluluklarında “UUID” duyarsınız.
Bir UUID, bir GUID ile aynı mıdır?
İşlevsel olarak, evet. GUID, UUID standardının Microsoft uygulamasıdır. RFC 9562 kapsamında davranışları özdeştir — bunları .NET, Java ve Python uygulamaları arasında birbirinin yerine kullanabilirsiniz.
Gerçek bir senaryoda iki UUID hiç çarpışabilir mi?
Matematiksel olarak mümkün, pratikte imkansız. UUID v4 için, %50 çarpışma olasılığına ulaşmak üzere yaklaşık 2.71 kentilyon ID üretmeniz gerekir. Generate-Random.org‘ya göre, saniyede 1 milyar UUID’yi 85 yıl boyunca üretmek size yalnızca tek bir çarpışma için %50 şans verir.
UUID’leri veritabanımda dizeler olarak mı yoksa ikili olarak mı depolamalıyım?
Her zaman Binary(16) veya doğal UUID türünü (PostgreSQL’de kullanılabilir) tercih edin. 36 karakterlik bir dize, iki katından fazla alan tüketir ve dizin aramalarını ve birleştirmeleri önemli ölçüde yavaşlatır.SnapUtils, RFC 9562’nin performans avantajlarının depolama kompakt kaldığında en üst düzeye ulaştığını belirtir.
UUID v4 yerine UUID v5’i ne zaman kullanmalıyım?
Belirleyici ID’lere ihtiyaç duyduğunuzda, yani aynı girdinin her zaman aynı UUID’yi ürettiği ve bir veritabanını sorgulamadığı durumda v5 kullanın. Tam rastgeleliğe ihtiyaç duyduğunuzda ve tanımlayıcının kaynağına tersine mühendislik uygulanamayacağından emin olmak istediğinizde v4 kullanın.
İlgili Yazılar

Font Generator: 2026’da Stilize Metnin Tam Haritası
Estetik Font Üreteci: Şık Unicode Metinler İçin Kapsamlı Rehber
Kaligrafi Font Oluşturucu: Zarif Metin Stilleri İçin Ücretsiz Çevrimiçi Araç