What Is a UUID? The Complete Guide to RFC 9562 and Modern Unique Identifiers
Quick Summary
- Every modern database, distributed system, and API uses
- Every modern database, distributed system, and API uses unique identifiers — and in 2026, the standard that governs them has fundamentally changed.
- Understanding RFC 9562: The Modern UUID Standard
Editorial Process
Reviewed by SectoJoy and published on May 7, 2026. This article is refreshed when product details, examples, or tool guidance change. Last updated May 15, 2026.
SectoJoy
I'm an indie hacker building iOS and web applications, with a focus on creating practical SaaS products. I specialise in AI SEO, constantly exploring how intelligent technologies can drive sustainable growth and efficiency.
Every modern database, distributed system, and API uses unique identifiers — and in 2026, the standard that governs them has fundamentally changed. UUID (Universally Unique Identifier) is a 128-bit label that can identify information across computer systems without any central coordination. Under the new RFC 9562 (which replaced RFC 4122 in May 2024), the landscape has shifted: UUID v4 remains the go-to for random IDs, but UUID v7 is now the recommended standard for database primary keys because its time-ordered structure prevents B-tree index fragmentation.
This guide covers the full picture: how UUIDs work, which version to use when, and how to implement them correctly.
Understanding RFC 9562: The Modern UUID Standard
A UUID is a 128-bit number that’s practically guaranteed to be unique — no central authority needed. According to Wikipedia, the chance of two UUIDs colliding is so close to zero it’s considered impossible for real-world applications. Different teams can label data independently, confident their IDs won’t clash.
In May 2024, the IETF published RFC 9562, retiring the old RFC 4122. The update responded to the demands of modern distributed systems, which needed IDs that are both unique and sortable by time. Three new versions were introduced: v6, v7, and v8.
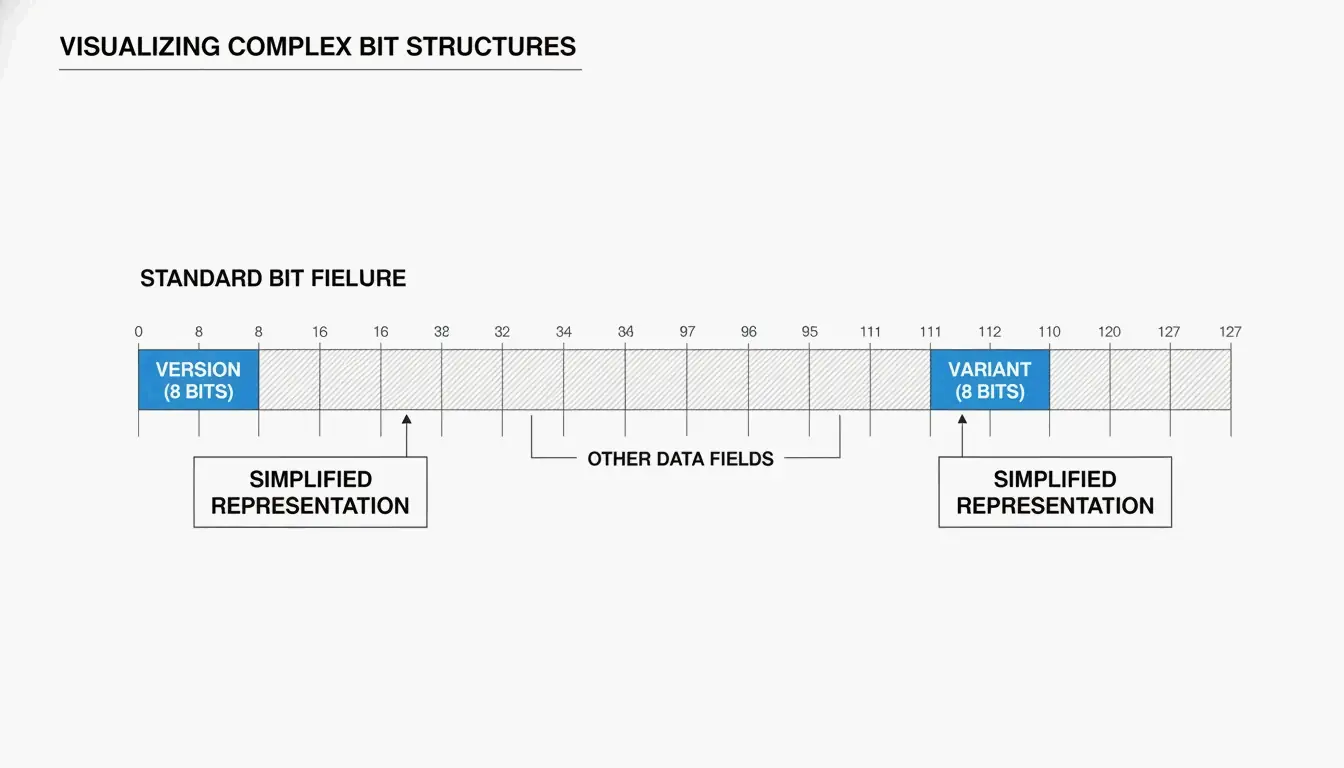
Anatomy of a UUID: Versions and Variants
You’ll typically see a UUID as 32 hexadecimal characters split into five groups by hyphens (8-4-4-4-12):
550e8400-e29b-41d4-a716-446655440000
^
version
Two key fields tell you how the UUID was generated:
| Field | Location | What It Tells You |
|---|---|---|
| Version bits | First 4 bits of the 7th byte (first char of the 3rd group) | Which algorithm was used (e.g., “4” = v4, “7” = v7) |
| Variant bits | 9th byte | The UUID variant — RFC 9562 uses a 10 bit pattern |
As SnapUtils explains, the variant bits separate modern RFC 9562 UUIDs from older Apollo or Microsoft formats.
Why UUID v7 Is the New Gold Standard for Databases
The biggest drawback of UUID v4 is that it’s completely random. When used as a primary key in a B-tree index, the database has to insert new rows at unpredictable positions. According to CreateUUID, this causes “page splits” — the database must constantly reorganize data to make room, leading to slower writes and wasted memory.
UUID v7 solves this by placing a 48-bit Unix Epoch timestamp (millisecond precision) at the start of the ID. This makes IDs monotonically increasing — new ones are always larger than old ones. The database can simply append to the end of the index, giving you the performance of a sequential integer with the global uniqueness of a UUID.
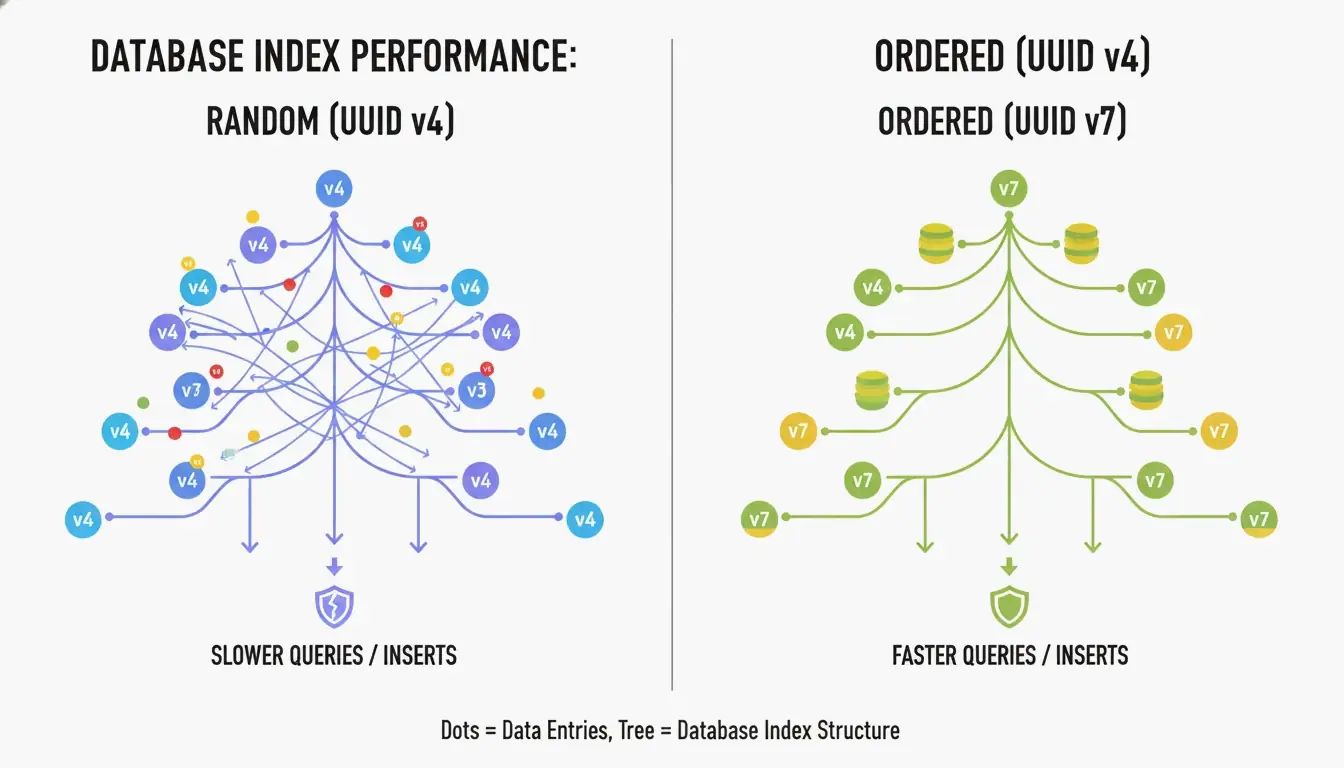
How UUID v7 Balances Time and Entropy
UUID v7 fills the remaining 74 bits using a CSPRNG (Cryptographically Secure Pseudo-Random Number Generator). According to Wikipedia, you’d need to generate about 1 billion UUIDs per second for 85 years to reach a 50% collision probability. For any real application, UUID v7 is effectively collision-proof.
Storage Best Practices: Binary(16) vs. String(36)
How you store UUIDs matters as much as which version you use:
| Storage Format | Space | Index Performance | Recommendation |
|---|---|---|---|
| Binary(16) | 16 bytes | High (compact) | Best practice |
| Native UUID type | 16 bytes | High (optimized) | Best for PostgreSQL |
| String (Char 36) | 36–72 bytes | Low (fragmented) | Avoid |
SnapUtils recommends always using native types over strings. In PostgreSQL, the native uuid type stores data in a compact 16-byte binary format while still supporting standard string-based queries.
UUID vs GUID: Is There a Difference?
A GUID (Globally Unique Identifier) is Microsoft’s implementation of the UUID standard. Historically, there was a difference in byte ordering (endianness) — early Microsoft GUIDs used little-endian for the first three fields, while standard UUIDs used big-endian (network byte order) (SnapUtils).
By 2026, this is mostly a naming convention. Under RFC 9562, they work identically. A Guid.NewGuid() in .NET is fully compatible with a uuid.uuid4() in Python. You’ll hear “GUID” in Windows/Azure circles and “UUID” in Linux and open-source communities.
Implementing Modern UUIDs: Language-by-Language
| Language | UUID v4 | UUID v7 |
|---|---|---|
| Python | Built-in uuid module |
uuid6 or uuid7 package |
| JavaScript | crypto.randomUUID() |
uuid npm package (v10+) |
| PostgreSQL | gen_random_uuid() (PG 13+) |
Native uuidv7() (PG 17+) or extensions |
| .NET | Guid.NewGuid() |
Community packages |
| Rust | uuid crate (v1.7+) |
uuid crate with v7 feature |
Deterministic IDs: UUID v5
If you need the same ID every time for a given input (like a URL or username), use UUID v5. It hashes a Namespace UUID and a name string using SHA-1 — perfect for deduplication when you can’t check a central database.
The Privacy Lesson of UUID v1
UUID v1 uses a timestamp and the computer’s MAC address. It’s been largely abandoned because it leaks hardware information. A famous example: the Melissa Virus creator was caught because UUIDs in infected Word documents contained his specific MAC address.
Advanced RFC 9562: v6, v8, and Special UUIDs
RFC 9562 added specialized versions for niche distributed system needs:
| Version | Purpose | Use When |
|---|---|---|
| v6 | Reordered v1 timestamp — sortable while keeping v1’s precision | Migrating legacy v1 systems |
| v8 | Custom — 122 bits for developer-defined data | Experimental or vendor-specific schemes |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
Null placeholder |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
Range endpoint marker |
Conclusion
RFC 9562 has updated unique identifiers for the modern cloud era. The practical guidance:
- Database primary keys → Use UUID v7 for time-ordered, fragmentation-free inserts
- General randomness → UUID v4 remains perfectly fine
- Deduplication → UUID v5 gives you deterministic IDs
- Storage → Always use Binary(16) or native UUID types, never strings
Action item: Check your database schemas. If you’re using UUID v4 as a primary key in tables with millions of rows, migrating to UUID v7 is a straightforward change that can significantly reduce index fragmentation and speed up queries.
FAQ
Is a UUID the same as a GUID?
Functionally, yes. A GUID is Microsoft’s implementation of the UUID standard. Under RFC 9562, they are identical in behavior — you can use them interchangeably across .NET, Java, and Python applications.
Can two UUIDs ever collide in a real-world scenario?
Mathematically possible, practically impossible. For UUID v4, you’d need to generate approximately 2.71 quintillion IDs to reach a 50% collision probability. According to Generate-Random.org, generating 1 billion UUIDs per second for 85 years gives you only a 50% chance of a single collision.
Should I store UUIDs as strings or binary in my database?
Always prefer Binary(16) or the native UUID type (available in PostgreSQL). A 36-character string consumes more than twice the space and significantly slows down index lookups and joins. SnapUtils notes that the performance benefits of RFC 9562 are maximized when storage stays compact.
When should I use UUID v5 instead of UUID v4?
Use v5 when you need deterministic IDs — the same input always produces the same UUID, without checking a database. Use v4 when you need complete randomness and want to ensure the identifier can’t be reverse-engineered to its source.
Frequently Asked Questions
UUID vs GUID: Is There a Difference?
A GUID (Globally Unique Identifier) is Microsoft’s implementation of the UUID standard. Historically, there was a difference in byte ordering (endianness) — early Microsoft GUIDs used little-endian for the first three fields, while standard UUIDs used big-endian (network byte order) (SnapUtils). By 2026, this is mostly a naming convention. Under RFC 9562, they work identically. A Guid.NewGuid() in .NET is fully compatible with a uuid.uuid4() in Python. You’ll hear “GUID” in Windows/Azure circles and “UUID” in Linux and open-source communities.
Is a UUID the same as a GUID?
Functionally, yes. A GUID is Microsoft’s implementation of the UUID standard. Under RFC 9562, they are identical in behavior — you can use them interchangeably across .NET, Java, and Python applications.
Can two UUIDs ever collide in a real-world scenario?
Mathematically possible, practically impossible. For UUID v4, you’d need to generate approximately 2.71 quintillion IDs to reach a 50% collision probability. According to Generate-Random.org, generating 1 billion UUIDs per second for 85 years gives you only a 50% chance of a single collision.
Should I store UUIDs as strings or binary in my database?
Always prefer Binary(16) or the native UUID type (available in PostgreSQL). A 36-character string consumes more than twice the space and significantly slows down index lookups and joins. SnapUtils notes that the performance benefits of RFC 9562 are maximized when storage stays compact.
When should I use UUID v5 instead of UUID v4?
Use v5 when you need deterministic IDs — the same input always produces the same UUID, without checking a database. Use v4 when you need complete randomness and want to ensure the identifier can’t be reverse-engineered to its source.
Related Posts

Font Generator: The Complete Map of Styled Text in 2026
Aesthetic Font Generator: The Ultimate Guide to Stylish Unicode Text
Calligraphy Font Generator: Free Online Tool for Elegant Text Styles