Qu’est-ce qu’un UUID ? Le guide complet de la RFC 9562 et des identifiants uniques modernes
Résumé rapide
- Toute base de données moderne, tout système distribué et toute API utilise des identifiants uniques — et en 2026, la norme qui les régit a fondamentalement changé
- Toute base de données moderne, tout système distribué et toute API utilise des identifiants uniques — et en 2026, la norme qui les régit a fondamentalement changé.
- Comprendre la RFC 9562 : la norme UUID moderne
Processus éditorial
Relu par SectoJoy et publié le 14 juin 2026. Cet article est mis à jour lorsque les détails du produit, les exemples ou les consignes d'utilisation évoluent. Dernière mise à jour : 14 juin 2026.
SectoJoy
Je suis un développeur indépendant créant des applications iOS et web, avec un focus sur les produits SaaS pratiques. Je me spécialise en SEO basé sur l'IA, en explorant constamment comment les technologies intelligentes peuvent stimuler la croissance durable et l'efficacité.
Toute base de données moderne, tout système distribué et toute API utilise des identifiants uniques — et en 2026, la norme qui les régit a fondamentalement changé. Un UUID (Universally Unique Identifier, identifiant unique universel) est une étiquette de 128 bits qui peut identifier des informations entre systèmes informatiques sans aucune coordination centrale. Sous la nouvelle RFC 9562 (qui a remplacé la RFC 4122 en mai 2024), le paysage a changé : UUID v4 reste la référence pour les ID aléatoires, mais UUID v7 est désormais la norme recommandée pour les clés primaires de bases de données, car sa structure ordonnée dans le temps empêche la fragmentation des index B-tree.
Ce guide couvre l’ensemble du sujet : le fonctionnement des UUID, la version à utiliser selon le cas, et comment les implémenter correctement.
Comprendre la RFC 9562 : la norme UUID moderne
Un UUID est un nombre de 128 bits dont l’unicité est pratiquement garantie — sans aucune autorité centrale. D’après Wikipédia, la probabilité que deux UUID entrent en collision est si proche de zéro qu’elle est considérée comme impossible pour les applications réelles. Différentes équipes peuvent étiqueter des données indépendamment, confiantes que leurs ID ne se heurteront pas.
En mai 2024, l’IETF a publié la RFC 9562, retirant l’ancienne RFC 4122. Cette mise à jour répondait aux exigences des systèmes distribués modernes, qui avaient besoin d’ID à la fois uniques et triables dans le temps. Trois nouvelles versions ont été introduites : v6, v7 et v8.
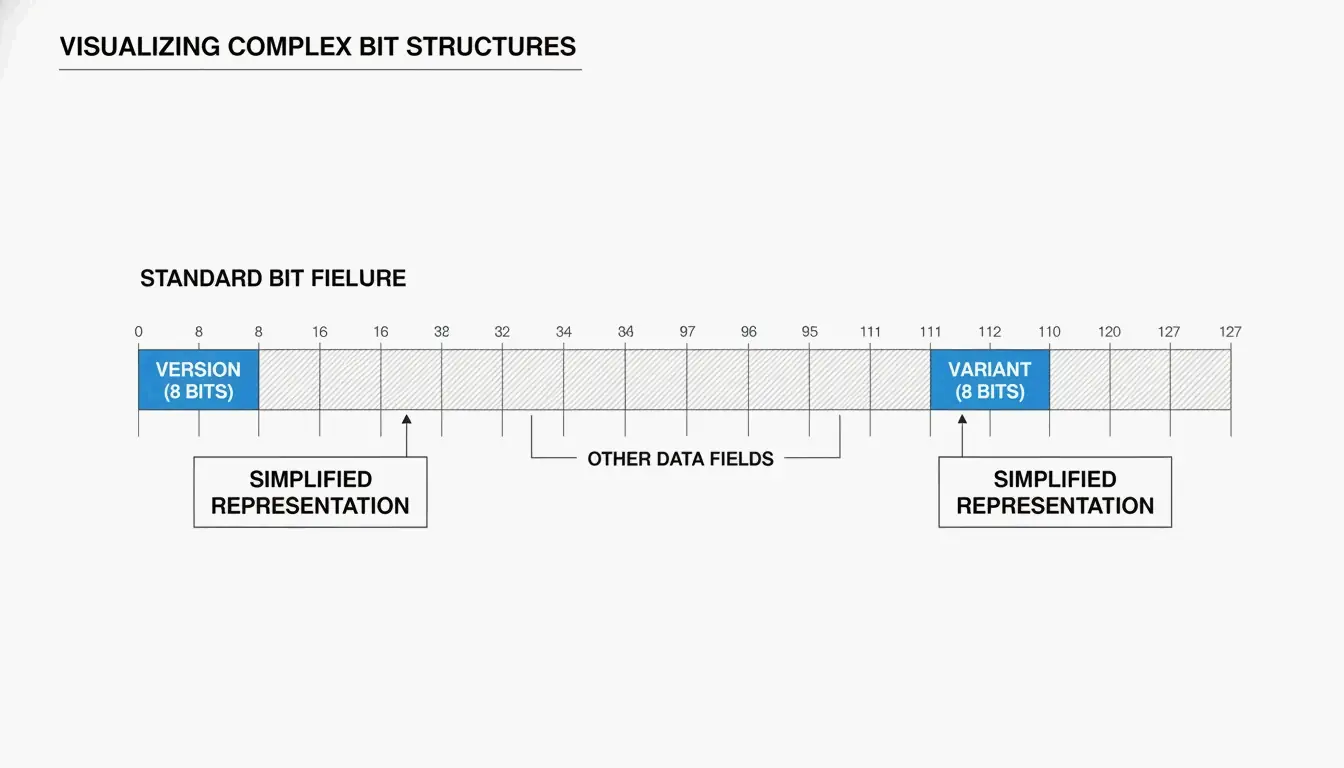
Anatomie d’un UUID : versions et variantes
Vous verrez généralement un UUID sous forme de 32 caractères hexadécimaux répartis en cinq groupes par des tirets (8-4-4-4-12) :
550e8400-e29b-41d4-a716-446655440000
^
version
Deux champs clés vous indiquent comment l’UUID a été généré :
| Champ | Emplacement | Ce qu’il indique |
|---|---|---|
| Bits de version | Les 4 premiers bits du 7e octet (premier caractère du 3e groupe) | L’algorithme utilisé (par ex. « 4 » = v4, « 7 » = v7) |
| Bits de variante | 9e octet | La variante de l’UUID — la RFC 9562 utilise un motif de bits 10 |
Comme l’explique SnapUtils, les bits de variante distinguent les UUID modernes de la RFC 9562 des anciens formats Apollo ou Microsoft.
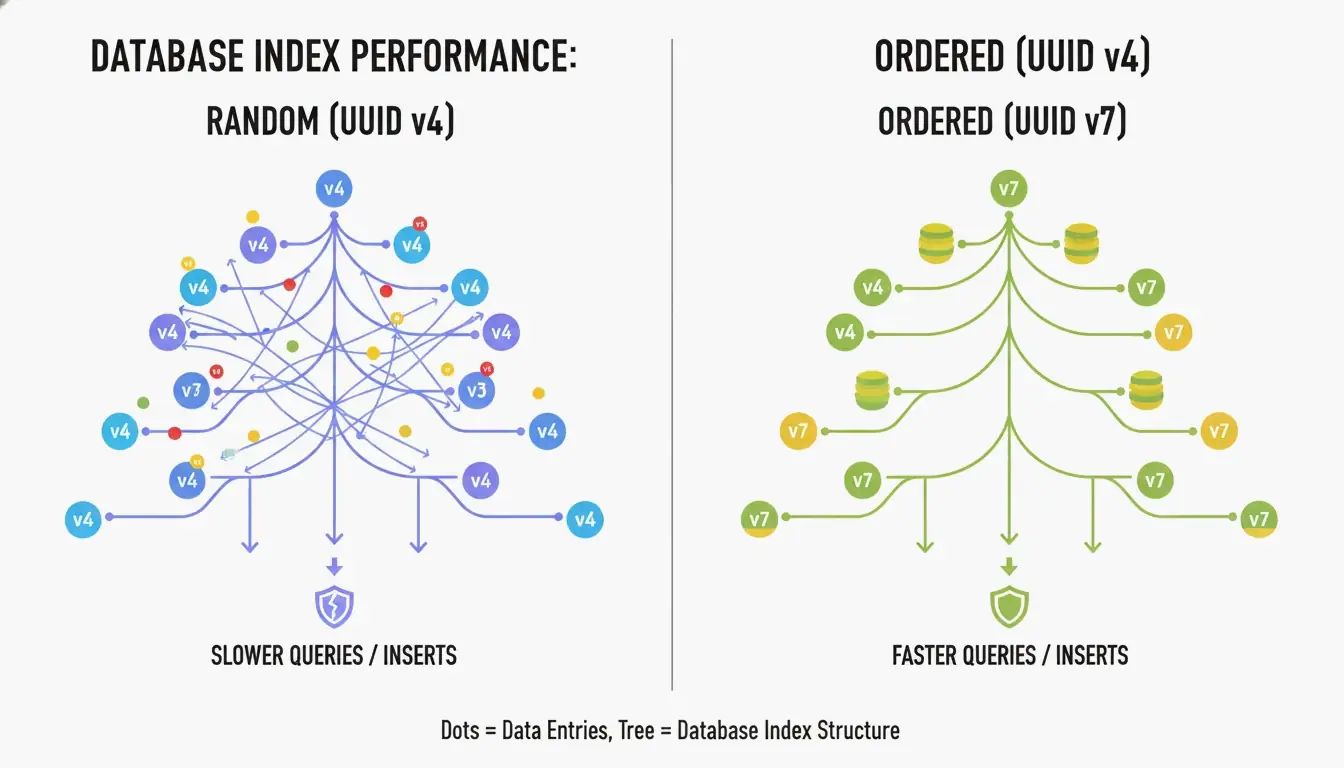
Pourquoi UUID v7 est le nouveau golden standard pour les bases de données
Le plus grand défaut d’UUID v4 est d’être entièrement aléatoire. Utilisé comme clé primaire dans un index B-tree, la base de données doit insérer de nouvelles lignes à des positions imprévisibles. D’après CreateUUID, cela provoque des « fractionnements de pages » (page splits) — la base doit constamment réorganiser les données pour faire de la place, ralentissant les écritures et gaspillant la mémoire.
UUID v7 y remédie en plaçant un horodatage Unix Epoch de 48 bits (précision milliseconde) au début de l’ID. Les ID deviennent alors strictement croissants — les nouveaux sont toujours supérieurs aux anciens. La base peut simplement les ajouter en fin d’index, vous offrant la performance d’un entier séquentiel avec l’unicité globale d’un UUID.
Comment UUID v7 équilibre temps et entropie
UUID v7 remplit les 74 bits restants avec un CSPRNG (générateur de nombres pseudo-aléatoires cryptographiquement sûr). Selon Wikipédia, il faudrait générer environ 1 milliard d’UUID par seconde pendant 85 ans pour atteindre une probabilité de collision de 50 %. Pour toute application réelle, UUID v7 est effectivement à l’abri des collisions.
Bonnes pratiques de stockage : Binary(16) contre String(36)
La façon dont vous stockez les UUID compte autant que la version choisie :
| Format de stockage | Espace | Performance d’index | Recommandation |
|---|---|---|---|
| Binary(16) | 16 octets | Élevée (compact) | Meilleure pratique |
| Type UUID natif | 16 octets | Élevée (optimisé) | Idéal pour PostgreSQL |
| Chaîne (Char 36) | 36–72 octets | Faible (fragmenté) | À éviter |
SnapUtils recommande de toujours utiliser les types natifs plutôt que des chaînes. Sous PostgreSQL, le type natif uuid stocke les données dans un format binaire compact de 16 octets tout en prenant en charge les requêtes standards basées sur des chaînes.
UUID contre GUID : y a-t-il une différence ?
Un GUID (Globally Unique Identifier, identifiant unique global) est l’implémentation Microsoft du standard UUID. Historiquement, il y avait une différence dans l’ordre des octets (endianness) — les premiers GUID Microsoft utilisaient l’ordre petit-boutiste pour les trois premiers champs, tandis que les UUID standards utilisaient l’ordre gros-boutiste (ordre des octets réseau) (SnapUtils).
En 2026, c’est surtout une convention de nommage. Sous la RFC 9562, ils fonctionnent à l’identique. Un Guid.NewGuid() en .NET est entièrement compatible avec un uuid.uuid4() en Python. Vous entendrez « GUID » dans les cercles Windows/Azure et « UUID » dans les communautés Linux et open source.
Implémenter des UUID modernes : langage par langage
| Langage | UUID v4 | UUID v7 |
|---|---|---|
| Python | Module uuid intégré |
Paquet uuid6 ou uuid7 |
| JavaScript | crypto.randomUUID() |
Paquet npm uuid (v10+) |
| PostgreSQL | gen_random_uuid() (PG 13+) |
uuidv7() natif (PG 17+) ou extensions |
| .NET | Guid.NewGuid() |
Paquets communautaires |
| Rust | crate uuid (v1.7+) |
crate uuid avec la feature v7 |
ID déterministes : UUID v5
Si vous avez besoin du même identifiant à chaque fois pour une entrée donnée (comme une URL ou un nom d’utilisateur), utilisez UUID v5. Il hache un UUID d’espace de noms et une chaîne de nom avec SHA-1 — parfait pour la déduplication quand vous ne pouvez pas interroger une base centrale.
La leçon de confidentialité d’UUID v1
UUID v1 utilise un horodatage et l’adresse MAC de l’ordinateur. Il a été largement abandonné parce qu’il fuite des informations matérielles. Un exemple célèbre : le créateur du virus Melissa a été identifié parce que les UUID des documents Word infectés contenaient son adresse MAC spécifique.
RFC 9562 avancée : v6, v8 et UUID spéciaux
La RFC 9562 a ajouté des versions spécialisées pour des besoins de systèmes distribués de niche :
| Version | Objectif | Quand l’utiliser |
|---|---|---|
| v6 | Horodatage v1 réordonné — triable tout en gardant la précision de v1 | Migration des systèmes v1 existants |
| v8 | Personnalisé — 122 bits pour des données définies par le développeur | Schémas expérimentaux ou spécifiques à un fournisseur |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
Espace réservé nul |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
Marqueur de fin de plage |
Conclusion
La RFC 9562 a mis à jour les identifiants uniques pour l’ère du cloud moderne. Les recommandations pratiques :
- Clés primaires de base de données → Utilisez UUID v7 pour des insertions ordonnées dans le temps et sans fragmentation
- Aléatoire général → UUID v4 reste tout à fait adapté
- Déduplication → UUID v5 fournit des ID déterministes
- Stockage → Utilisez toujours Binary(16) ou les types UUID natifs, jamais de chaînes
Action : Vérifiez vos schémas de base de données. Si vous utilisez UUID v4 comme clé primaire dans des tables de plusieurs millions de lignes, migrer vers UUID v7 est un changement simple qui peut réduire considérablement la fragmentation d’index et accélérer les requêtes.
FAQ
Un UUID est-il identique à un GUID ?
Fonctionnellement, oui. Un GUID est l’implémentation Microsoft du standard UUID. Sous la RFC 9562, leur comportement est identique — vous pouvez les utiliser indifféremment entre les applications .NET, Java et Python.
Deux UUID peuvent-ils entrer en collision dans un scénario réel ?
Mathématiquement possible, pratiquement impossible. Pour UUID v4, il faudrait générer environ 2,71 trillions de trillions d’ID pour atteindre une probabilité de collision de 50 %. Selon Generate-Random.org, générer 1 milliard d’UUID par seconde pendant 85 ans ne vous donne que 50 % de chances d’obtenir une seule collision.
Faut-il stocker les UUID sous forme de chaînes ou de binaire en base de données ?
Préférez toujours Binary(16) ou le type UUID natif (disponible dans PostgreSQL). Une chaîne de 36 caractères consomme plus de deux fois plus d’espace et ralentit considérablement les recherches d’index et les jointures.SnapUtils note que les bénéfices de performance de la RFC 9562 sont maximisés lorsque le stockage reste compact.
Quand utiliser UUID v5 plutôt qu’UUID v4 ?
Utilisez v5 lorsque vous avez besoin d’ID déterministes — la même entrée produit toujours le même UUID, sans consulter une base. Utilisez v4 lorsque vous voulez un aléatoire complet et garantir que l’identifiant ne puisse pas être reconstitué pour remonter à sa source.
Questions fréquentes
UUID contre GUID : y a-t-il une différence ?
Un GUID (Globally Unique Identifier, identifiant unique global) est l’implémentation Microsoft du standard UUID. Historiquement, il y avait une différence dans l’ordre des octets (endianness) — les premiers GUID Microsoft utilisaient l’ordre petit-boutiste pour les trois premiers champs, tandis que les UUID standards utilisaient l’ordre gros-boutiste (ordre des octets réseau) (SnapUtils). En 2026, c’est surtout une convention de nommage. Sous la RFC 9562, ils fonctionnent à l’identique. Un Guid.NewGuid() en .NET est entièrement compatible avec un uuid.uuid4() en Python. Vous entendrez « GUID » dans les cercles Windows/Azure et « UUID » dans les communautés Linux et open source.
Un UUID est-il identique à un GUID ?
Fonctionnellement, oui. Un GUID est l’implémentation Microsoft du standard UUID. Sous la RFC 9562, leur comportement est identique — vous pouvez les utiliser indifféremment entre les applications .NET, Java et Python.
Deux UUID peuvent-ils entrer en collision dans un scénario réel ?
Mathématiquement possible, pratiquement impossible. Pour UUID v4, il faudrait générer environ 2,71 trillions de trillions d’ID pour atteindre une probabilité de collision de 50 %. Selon Generate-Random.org, générer 1 milliard d’UUID par seconde pendant 85 ans ne vous donne que 50 % de chances d’obtenir une seule collision.
Faut-il stocker les UUID sous forme de chaînes ou de binaire en base de données ?
Préférez toujours Binary(16) ou le type UUID natif (disponible dans PostgreSQL). Une chaîne de 36 caractères consomme plus de deux fois plus d’espace et ralentit considérablement les recherches d’index et les jointures.SnapUtils note que les bénéfices de performance de la RFC 9562 sont maximisés lorsque le stockage reste compact.
Quand utiliser UUID v5 plutôt qu’UUID v4 ?
Utilisez v5 lorsque vous avez besoin d’ID déterministes — la même entrée produit toujours le même UUID, sans consulter une base. Utilisez v4 lorsque vous voulez un aléatoire complet et garantir que l’identifiant ne puisse pas être reconstitué pour remonter à sa source.
Articles associés

Générateur de polices : la carte complète du texte stylé en 2026
Générateur de polices esthétiques : le guide ultime du texte Unicode stylé
Générateur de polices calligraphiques : outil en ligne gratuit pour des styles de texte élégants